7 years, 3 months ago
A cooperative benchmark: Announcing the Hanabi Learning Environment
Today, as part of a DeepMind / Google Brain team collaboration, we’re releasing the Hanabi Learning Environment (code and paper), a research platform for multiagent learning and emergent communication based on the popular card game Hanabi. The HLE provides an interface for AI agents to play the game, and comes packaged with a learning agent based on the Dopamine framework. The platform’s name echoes that of the highly-successful Arcade Learning Environment.
Hanabi is a two- to five- player cooperative game designed by Antoine Bauza. It was a revelation at the 2012 Internationale Spieltage in Essen and went on to win Spiel des Jahres, the most prestigious prize for board games, in 2013. In Hanabi, players work together to build five card sequences, each of a different colour. What makes the game interesting is that players can see their teammates’ cards, but not their own. Communication happens in great part through “hint” moves, where one person tells another something about their cards so that they know what to play or discard. Because there is a limited number of hints that can be given, good players communicate strategically and make use of conventions, for example “discard your oldest card first”.
The apex of strategic communication in Hanabi is what experts call a finesse: a finesse is a move played by a teammate that at first glance seems bad (to us), but is in fact brilliant if we assume our teammate knows something we don’t. Supposing our fellow players can play well, we can rule out this “first glance” explanation and conclude something about our own cards. A typical reasoning based on a finesse might be: “My teammate knows the ‘red 2’ is highly valuable. Yet she purposefully discarded her ‘red 2’. The only logical explanation is that I’m currently holding the other ‘red 2’.” (If you play the card game Hearts, you will be familiar with similar plays around the queen of spades). As a result of a finesse, players end up forming complex explanations about the game. From an emergent communication perspective, finesses are fascinating because both playing and understanding them requires going beyond the literal meaning of hints and inferring the intent of teammates – what’s sometimes been called theory of mind.
So, how do existing reinforcement learning methods fare in Hanabi? Not as well as you might think. Our first experiment pushed the envelope by giving an effectively unlimited amount of training to a modified Importance Weighted Actor-Learner. We settled on 20 billion moves as “effectively unlimited”: this number corresponds to roughly 300 million games or 166 million hours of human game play (if one assumes a casual player takes about 30 seconds per move). The algorithm was trained with copies of itself, in what we call the self-play setting. While the algorithm can learn successful conventions in the two-player setting (22.73 points on average, out of a possible total of 25), it performs substantially worse than expert humans or hand-coded bots in four- and five- player settings:
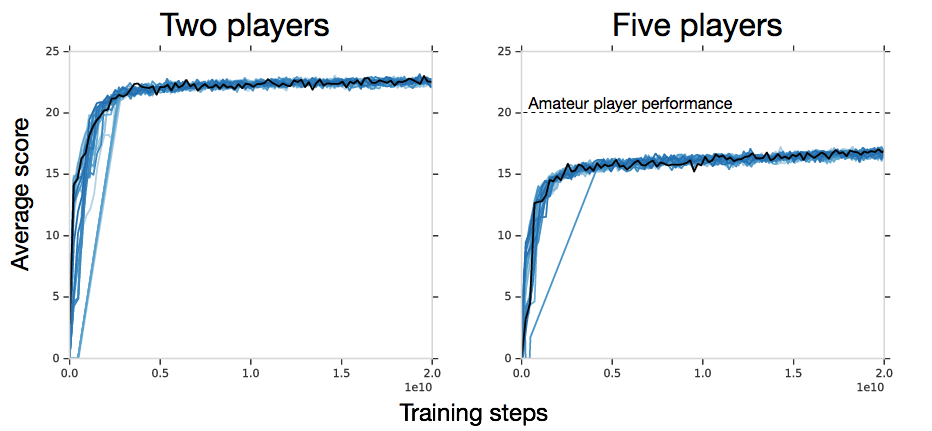
We confirmed these findings in a second experiment, using a more modest budget of 100 million moves and the modified Rainbow architecture provided with our release (try it for yourself: you can train a 15-point agent on a single GPU in about 16 hours). Rainbow also performs decently well in the 2-player setting but its performance is rather poor in the 4- and 5-player settings. While there are certainly techniques for improving these scores (the BAD method, also discussed in the paper, is one), the number of samples needed to get there suggests that discovering conventions in Hanabi remains an unsolved problem.
And yet, cracking the self-play setting will only be the beginning. Successful communication in the wild requires both efficient coding (don’t waste words) but also adaptability (understand the listener). When we meet someone new, we might not agree on all terms of the language, and as a result we tend to keep things a little simpler. For example, I leave operator norms and Lyapunov functions out of (most) social meetings. This need for adaptability is central to Hanabi: when playing with a new group, one takes fewer risks – perhaps doing without finesses altogether, or waiting until a teammate initiates such a move. While humans are great at adapting to unfamiliar listeners, our current best agents are not: they follow conventions that are both intricate and quite rigid.
The situation where an agent is asked to cooperate with unfamiliar agents is called ad hoc team play. Where the self-play setting requires us to learn the best convention, ad hoc team play requires adapting to a priori unknown conventions. In our work we found that agents trained with self-play fail dramatically in the ad hoc setting. In one experiment, we took 10 fully-trained actor-learner agents and paired them up into new teams. Recall that in the 2-player setting, actor-learner agents achieve over 23 points. By contrast, the new teams strike out almost immediately, with an average of 2 or 3 points. We found it useful to visualize this effect using something akin to a correlation matrix, with the diagonal corresponding to the self-play evaluation:
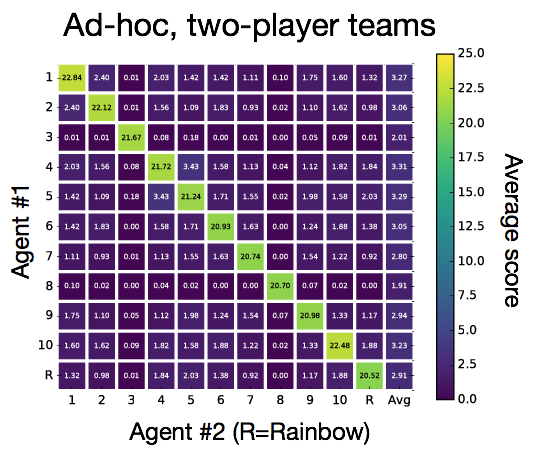
To put things in perspective, a simple hand-coded strategy that provides hints at random gets an average of 5.1 points. Of course, this is not too surprising, given that our self-play agents are not designed to adapt to other players. Still, the magnitude of the effect (from near-perfect to near-zero) shows this is an important shortcoming of existing agents.
It’s clear, considering the results of the last decade, that machine learning holds incredible potential. Communication, and the ability to infer intent, are one of the “next big steps”. Similar to how Atari 2600 games invigorated the field of deep reinforcement learning, Hanabi is a great Petri dish for testing out how algorithms can learn to cooperate in a scenario that is both dear to humans and challenging to AI. I look forward to seeing the beautiful cooperation that must emerge from Hanabi research.
Acknowledgements.
This is the work of a big team, and I’d like to thank all the paper authors, in particular Nolan Bard, Jakob Foerster, Sarath Chandar, and Neil Burch for pulling all the stops to get this paper out to press. Thanks also to Alden Christianson from DeepMind in Edmonton for carrying things forward throughout the project. Finally, huge thanks to the creator of Hanabi, Antoine Bauza, as well as Matthieu d'Epenoux and the folks at Cocktail Games who graciously supported us in our mission to bring Hanabi to AI researchers.
Appendix.
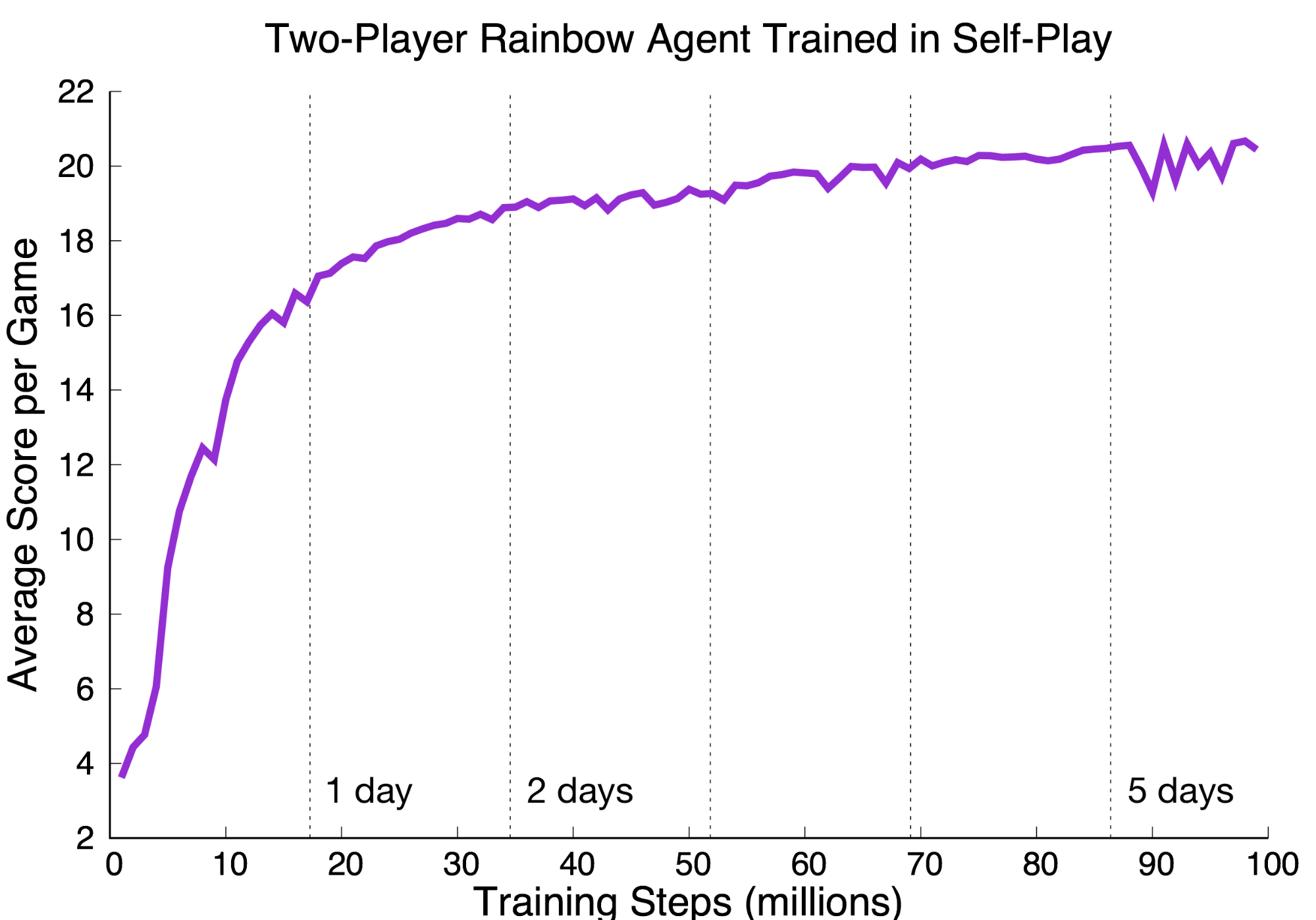
Here’s what a typical learning curve for our Dopamine agent looks like, trained from my desktop GPU. Scores are time-averaged per million steps.