Introducing the ALE 0.6
ALE 0.6 is out!

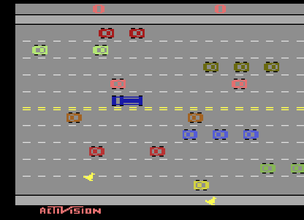
It’s been quite a long time since the Arcade Learning Environment saw any significant changes. Today we’re releasing version 0.6, which provides support for two new features: modes and difficulties. As it turns out, there are more buttons on the Atari 2600 console than the ALE lets you play with. The select button is typically used to determine which of the many game modes to play. For example, there are a total of 8 modes in Freeway, including different car formations, trucks, and varying vehicle speeds. Here's modes 0 to 2, plus two modes from Space Invaders:



There’s also difficulty switches. In almost all games, these switches make the game harder in one way or another. Looking at Space Invaders again, setting the switch to the ‘hard’ setting makes the laser cannon easier to hit:


What does that mean for AI research? For starters, our AI agents have all been playing the easiest levels of the 60 games available through the ALE. Although in many cases we don’t expect this to be a problem, this certainly adds a few extra challenges (in modes 9–16 in Space Invaders, the invaders are … invisible!) Breakout, an otherwise reasonably easy game for our agents, requires memory in the latter modes: the bricks only briefly flash on the screen when you hit them. Because each mode and difficulty combination (what we call a flavour) is a slight variation on the base game, the 0.6 release gives us a beautiful framework for testing transfer learning, lifelong learning, meta-learning methods, or simply how well our agents generalize: train on one mode, test on the rest, for example. I’ve no doubt researchers will get quite creative with this – we’ve certainly got a few ideas of our own.
Finally, sticky actions were added in ALE 0.5 but never quite given the spotlight. These were added in response to concerns that agents could learn frame-perfect policies that were in many ways flawed. Sticky actions are an unintrusive solution: at every frame, the environment decides whether to execute the previous action (hence the "sticky" epithet) or use the current input. Sticky actions aren't tied to agent-centric choices such as the frame skip length; they punish policies that rely on perfect reaction time; yet they still let us achieve superhuman scores. Our paper (reference below) goes into this choice in greater detail, and also provides a comparison with other methods previously used.
ALE 0.6 also brings in a number of architectural changes, most importantly a switch to C++11. This let us simplify the new logic a little and makes the code generally cleaner. We’re also supporting a number of additional games provided by various users in the last two years – Warren Robinett’s Adventure promises to be a real challenge for learning agents. As usual, the code is available via GitHub.
Before we wrap this up, here’s to all the incredible contributors in the last two years that have helped make this possible, and in particular Nicolas Carion who wrote much of the code for selecting modes and difficulties. A shout-out also to OpenAI for making the ALE accessible via their Gym interface. This year I had the great pleasure of meeting Bradford Mott, the original Stella programmer, at AIIDE-17: last but not least, a huge thank you to the Stella developers who made their emulator accessible.
One more thing. If you like these new features and use them in your published work, please cite the following paper:
Marlos C. Machado, Marc G. Bellemare, Erik Talvitie, Joel Veness, Matthew Hausknecht, Michael Bowling. Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents, arXiv, 2017.
Marc G. Bellemare & Marlos C. Machado
