
Marc G. Bellemare
Chief Scientific Officer, Reliant AIAdjunct Professor, McGill University
Adjunct Professor, Université de Montréal
Canada CIFAR AI Chair, Mila
Associate Fellow, CIFAR LMB Program
About
Co-founder of Reliant AI, a generative AI startup based in Montréal, Canada and Berlin, Germany.
Core industry member and Canada CIFAR AI Chair at Mila. My PhD research introduced the Atari 2600 as a large-scale benchmark for reinforcement learning research. It led to the emergence of the field now known as deep reinforcement learning (our paper in Nature). In more recent work my research group has continued to push the frontiers of applied deep reinforcement learning, including the first major commercial application of RL as part of a joint project with Loon. My PhD advisors are Michael Bowling and Joel Veness.
I previously led the reinforcement learning efforts of the Google Brain team in Montréal and before then worked as a research scientist at DeepMind in the UK.
Research highlights
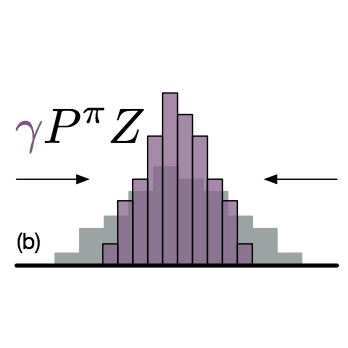
Distributional Reinforcement Learning
MIT Press, Spring 2023
Our book surveys the core elements of distributional reinforcement learning, which seeks to understand how the various sources of randomness in an environment combine to produce complex distributions of outcomes, and how these distributions can be estimated from experience. Among others, the theory has been used as a model of dopaminergic neurons in the brain, to reduce the risk of failure in robotic grasping, and to achieve state-of-the-art performance in simulated car racing and video-game playing. With Will Dabney and Mark Rowland. Draft available at http://distributional-rl.org.
Further reading
Talk at the University of British Columbia (2020)A distributional perspective on reinforcement learning (ICML, 2017)

Autonomous Navigation of Stratospheric Balloons
Nature, 2020
As part of a collaboration with Loon, we used deep reinforcement learning to improve the navigation capabilities of stratospheric balloons. Based on a 13-balloon, 39-day controlled experiment over the Pacific Ocean, we found evidence of significantly improved power efficiency, increased time within range of a designated station, and determined that the controller had discovered new navigation techniques. Training the controller was made possible by a statistically plausible simulator that could model the wind field's "known unknowns" and the effect of the diurnal cycle on power availability. Read our 2020 paper here.
In 2022 we open-sourced a high-fidelity replica of the original simulator, offering a unique challenge for reinforcement learning algorithms. Read the blog post.
In the press
New Scientist, Google's AI can keep Loon balloons flying for over 300 days in a rowLa Presse, Loon fait appel à l'expertise en intelligence artificielle de Google Montréal
Heise Online, Google: KI hält Stratosphärenballons in festem Gebiet

The Arcade Learning Environment
Journal of Artificial Intelligence Research, 2013
The Arcade Learning Environment (ALE) is a reinforcement-learning interface that enables artificial agents to play Atari 2600 games. We released the first complete version of the benchmark in 2012 (see paper in the Journal of Artificial Intelligence Research). The ALE was popularized by the release of the highly-successful DQN algorithm (see our 2015 paper in Nature) and continues to support deep reinforcement learning research today.
Further reading
Revisiting the arcade learning environment: evaluation protocols and open problems for general agents (JAIR, 2018)Selected publications
My academic research has focused on two complementary problems in reinforcement learning. First comes the problem of representation: How should a learning system structure and update its knowledge about the environment it operates in? The second problem is concerned with exploration: How should the same learning system organize its decisions to be maximally effective at discovering its environment, and in particular to be able to rapidly acquire information to build better representations?
On bonus-based exploration methods in the arcade learning environment. Adrien Ali Taiga, William Fedus, Marlos C. Machado, Aaron Courville, Marc G. Bellemare. ICLR 2020. Also best paper award at ICML Workshop on Exploration in RL, 2019.
DeepMDP: Learning continuous latent space models for representation learning. Carles Gelada, Saurabh Kumar, Jacob Buckman, Ofir Nachum, Marc G. Bellemare. ICML 2019.
A geometric perspective on optimal representations for reinforcement learning. Marc G. Bellemare, Will Dabney, Robert Dadashi, Adrien Ali Taiga, Pablo Samuel Castro, Nicolas Le Roux, Dale Schuurmans, Tor Lattimore, Clare Lyle. NeurIPS 2019.
Dopamine: A research framework for deep reinforcement learning. Pablo Samuel Castro, Subhodeep Moitra, Carles Gelada, Saurabh Kumar, Marc G. Bellemare. 2018. [GitHub]
Unifying count-based exploration and intrinsic motivation. Marc G. Bellemare, Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Rémi Munos. NeurIPS 2016.
Students
Current
Jacob Buckman (PhD), with Doina Precup. Currently: Manifest AI.
Harley Wiltzer (PhD), with David Meger.
Pierluca D'Oro (PhD), with Pierre-Luc Bacon. Also at FAIR (Meta).
Nathan U. Rahn (PhD), with Doina Precup.
Jesse Farebrother (PhD), with David Meger. On internship at FAIR (Meta).
Graduated
Charline Le Lan (PhD, Oxford University, 2023). Now: Google DeepMind.
Max Schwarzer (PhD 2023). Now: OpenAI.
Johan Obando Céron (MSc 2023). Now: PhD at Mila.
Harley Wiltzer (MSc 2021).
Marlos C. Machado (PhD 2019). Now: University of Alberta
Philip Amortila (MSc 2019). Now: PhD at UIUC.
Vishal Jain (MSc 2019). Now: Staff Data Scientist, Ushur.